|
Implementing A Scripting Engine - Part 9 - Advanced Subjects by (12 August 1999) |
Return to The Archives |
Introduction
 |
|
Now that you have been playing with the finished scripting sample for a bit, and
maybe have implemented some new features, you're probably wondering when we're
getting to the good stuff. Allow me to warn you that most this good stuff is a LOT of work (which is why I won't present any more sample code :-). I will discuss several advanced scripting subjects and give a general idea how (I think) they're implemented. But first: |
|
A lockup-resistent VM
|
|
Some time ago Joseph Hall gave me a great tip for dealing with infinite-looping
script code. His idea is as follows: give the virtual machine a maximum number
of opcodes to execute each time you call it, and let it resume next frame if
it's not done yet; this is the virtual equivalent to a CPU-burst in pre-emptive
multitasking. This way your game engine can keep running even when your script
code hangs; it could even automatically detect that the script is constantly
looping (i.e. stuck in one part of the code) and reset the VM. Now, let's see how we could expand our language: |
|
Functions
|
|
Adding functions to your scripting language isn't very hard, but it introduces
the new concepts of parameters and local variables. For both of these, the stack
is used. Before a function call the application pushes the parameters onto the
stack. The function then reserves space on the same stack for its local
variables. Then the function executes, using the reserved stack space to read
values from and write values into. In our sample compiler, we've only pushed to
and popped from the top of the stack, but now you also have to access memory
adresses somewhere in the middle of the stack. For functions you need two special opcodes: CALL and RETURN. CALL is an unconditional jump that saves the instruction pointer on the stack. RETURN is reads the stored instruction pointer and jumps back to the instruction after CALL. The most logical thing to do is to let the caller (not the function) remove the parameters from the stack; after all, the caller put them there in the first place. This also allows for a simple mechanism of "output parameters": the function changes one of its parameters and the caller stores this value into a variable afterwards. A function's return value can also be seen as an output parameter. Function headers can be stored in the symbol table. With them you could store links to its parameters and local variables (which can each be separate symbol table entries). During code generation you can store the start address of the function in the symbol table as well. Overloading Function overloading can be a very nice feature in a language, but implementing it can be tricky. The problem is finding the "right" function to call in case none of the available function headers match exactly with the supplied parameter types. In this case, you will have to coerce some of the parameters to different types to get a complete match. The question is, of course, what parameters to coerce and what type to coerce them to. Most compilers try to match the call to each of the alternatives and choose the one with the smallest number of coercions. Some compilers allow double coercions (i.e. bool -> int, then int -> unsigned), further complicating matters. Keep it simple is my advice. Operators can just be seen as functions that are called using a different syntax; if you treat all your operators this way (not making them actual function (slow) but rather inline functions or macros), you can easily extend function overloading to operator overloading. |
|
Classes
|
|
If you want to implement classes in your language, decide exactly which features
you want to support. Supporting full C++ classes, including multiple
inheritance, access restrictions, dynamic casts, virtual functions, etc. is very
hard and I don't recommend starting with all that. A simple class system with
single inheritance is a good starting point. You can always expand it later if
the need arises. Classes, and structs, are compound data types: they contain a number of data members, and are linked to a number of methods or member functions. You could store a member list in your symbol table, which links to other symbol table entries that are the separate members. This allows you to easily find the offset of a member in the structure. Inheritance Single inheritance is relatively easy: when you're looking for a member in an object, check whether the member's in the child class; if not, check its parent class. The memory layout for child classes is very simple: first you store the parent, then its child, another child, etc. So downcasting is implicit: if you treat a Cat pointer as an Animal pointer, that simply means your program has access to fewer members, but the address of the pointer need not change. Multiple inheritance introduces ambiguity problems when calling member functions or accessing data members. Consider this: Two classes 'B' and 'C' are child classes of the same class 'A'. Then someone creates a class 'D' that's derived from both 'B' and 'C'. Now, if class 'A' has a public member function DoSomething, and the programmer calls DoSomething on an object of type D, you don't know which of the two DoSomething's to call: the one that acts on the 'A' part of 'B' or on the 'A' part of 'C'.. Okay, maybe a picture will make it clearer: 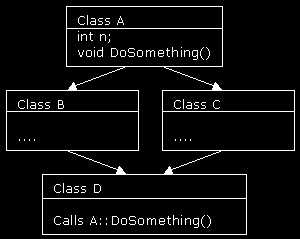 Virtual functions Virtual functions are a way of creating polymorphic (lit. "of many forms") types; e.g. an Animal class that contains a virtual function MakeSound(), and child classes Cat and Dog that each implement these functions in a different way (I'll let you figure out how exactly they would implement them ;-). So when you call the MakeSound function of an Animal object, you don't know (and don't need to know) what kind of animal is making a sound. Virtual functions are implemented by creating a so-called vtable. When the parent class declares a function as being virtual, it's added to the vtable for that class. Each child class now gets its own version of the vtable, so that, although the caller sees no difference between the tables, different functions are called based on the object's actual type. Dynamic casts Dynamic casts can be handy: for example, in UnrealScript you can not only downcast an object (cast it to its parent type), but also upcast it (cast it to an object of a child class), if the object is indeed an object of the child class. This means you need a way of determining whether an object of type Parent is really a Child1 object that's been cast down (in which case it can be cast up) or a Child2 object (in which case it can't be cast up). In the latest C++ compilers you can do the same with the dynamic_cast<...> operator. How to determine this? Each object will have to have a unique identification number, perhaps an index to a table of classes and their parents. By using this number you can always tell what kind of object it really is. Type variables Another fun thing is to allow type variables. This allows you to dynamically create objects of variable types. An example. Say you have a game with a cloning machine. An enemy walks in and two identical enemies walk out. You could use a big switch statement that contains all possible enemies, but that's not a very extensible approach. So you store the enemy's type and tell the game to create a monster of that type. In some imaginary language's code:
You can pass type variables to functions; this will make them very flexible indeed, as you can use the same function to create and manipulate many different kinds of objects! For type variables you need to expand the table of classes and their parent class to include every class' size; otherwise you have no way of dynamically creating them. |
|
Game-specific Language Constructs
|
|
UnrealScript was (as far as I know) the first language to offer two language
features that are very useful in games: states and latent code. States Classes in UnrealScript can have several states; an object is always in exactly one state. Based on which state the object is in, different functions are executed for that object. So if the object is an enemy and it's in the Angry state, the Angry version of the function SeePlayer would be executed and the enemy would start attacking the player. If the enemy is in the Frightened state, another SeePlayer function (with the same parameter types) would be called and would make the enemy flee. States aren't very hard to add, although it requires some work; the state is an extra (invisible) class member and whenever a state-specific function is called the appropriate version of the function is executed. This could easilt be done with a jump table, using the state number as an index. States can have their own out-of-function code, known in UnrealScript as state code. This is handy in combination with the next construct: latent functions. Latent functions Latent functions are quite hard to implement, but very cool: a latent function takes some game time to execute; in other words, the process can start a function Wait or Animate that starts waiting or animating the creature, and when the animation is done the code resumes execution. This is a great feature to have for AI scripts. The problem with (and strength of) latent code is that it's essentially running in parallel with the other code. Every now and then a piece of latent code is executed, then it's stopped again. So we have to remember the latent code instruction pointer. And when the object changes states, you'll also want it to execute other latent code. We can see the reason UnrealScript only allow latent functions to be called from state code, not from normal functions: if latent functions could be called from anywhere, every object could essentially have many 'threads' running in parallel.. this would require a lot of bookkeeping and would become slow. Also, synchronisation problems would occur: one object thread would set a member variable to a certain value, then another thread would become active and modify it again.. We would need to implement a full threading system if we wanted to allow this. |
|
That's it for now...
|
|
Well, I hope this got your imagination going. There's lots of features your
scripting language could offer; but you're going to have to limit yourself to
the ones you really need if you ever want to finish it. This was probably the last part of this tutorial series. I really enjoyed writing it! If you feel some aspect has not gotten enough attention, let me know, and maybe I'll do an extra part. Of course, if you have any other questions I'd also like to hear from you. Good luck, and keep on scripting! ;-) Jan Niestadt |
|
Quote!
|
|
"He stared at it for some time as things began slowly to reassemble
themselves in his mind. He wondered what he should do, but
he only wondered it idly. Around him people were beginning
to rush and shout a lot, but it was suddenly very clear to him
that there was nothing to be done, not now or ever. Through
the new strangeness of noise and light he could just make out
the shape of Ford Prefect sitting back and laughing wildly. A tremendous feeling of peace came over him. He knew that at last, for once and for ever, it was now all, finally, over." HHG 5:25 |